
# lab-5 实验报告
# 实验思考题
# Thinking 5.1
查阅资料,了解 Linux/Unix 的 /proc 文件系统是什么?有什么作用? Windows 操作系统又是如何实现这些功能的?proc 文件系统这样的设计有什么好处和可以改进的地方?
答案
/proc 文件系统是一个虚拟文件系统,通过它可以使用一种新的方法在 Linux 内核空间和用户间之间进行通信。在 /proc 文件系统中,我们可以将对虚拟文件的读写作为与内核中实体进行通信的一种手段,但是与普通文件不同的是,这些虚拟文件的内容都是动态创建的。其只存在于内存中,而不占用外存空间。它提供了新的一种在用户空间和内核空间中进行通信的模式。用户和应用程序可以通过 proc 得到系统的信息,并可以改变内核的某些参数,这个过程是动态的,随着内核参数的改变而改变。
Win32 API 是 Windows 操作系统内核与应用程序之间的界面,它将内核提供的功能进行函数包装,应用程序通过调用相关函数而获得相应的系统功能,相关函数接着调用系统服务接口,最后由系统服务接口调用内核模式中的服务例程。
好处:为了降低内核调试和学习的难度,内核开发者们在内核中添加了一些属性专门用于调试内核,proc 文件系统就是一个尝试。我们通过实时的观察 /proc/xxx 文件,来观看内核中特定数据结构的值。在我们添加一个新功能的前后来对比,就可以知道这个新功能产生的影响对还是不对。/proc 文件系统的设计将对内核信息的访问交互抽象为对文件的访问修改,简化了交互过程。
可以改进的地方:访问的容易必将带来安全性的隐患,程序可能获取到一些或者可能会很容易修改一些很重要的内核设置,对内核造成损害
# Thinking 5.2
如果我们通过 kseg0 读写设备,我们对于设备的写入会缓存到 Cache 中。通过 kseg0 访问设备是一种错误的行为,在实际编写代码的时候这么做会引发不可预知的问题。请你思考:这么做这会引起什么问题?对于不同种类的设备(如我们提到的串口设备和 IDE 磁盘)的操作会有差异吗?可以从缓存的性质和缓存刷新的策略来考虑。
答案
外设更新后对内存也进行了更新,但是 cache 中的没有被更新,如果我们通过 kseg0 来访问设备,那么就会导致总是优先通过 cache 获取缓存的数据,而缓存的数据没有更新,从而导致错误,即我们获取的数据并不是最新的。
自盘作为块设备,总是以块为单位进行读写,而且会经常进行读写,写的时候相应的内存会标记为 dirty,从而写回,更新缓存,因此这种错误对磁盘出现概率较小;但是与之相反,串口设备等字符型设备就很容易发生这种错误。
# Thinking 5.3
比较 MOS 操作系统的文件控制块和 Unix/Linux 操作系统的 inode 及相关概念,试述二者的不同之处。
答案
现代 Linux 使用的应该是一种日志型文件系统,是如下图有 log 的,添加或删除文件是通过修改 log,然后最后一起同步时写入的,这样会避免突然断电等导致的数据不一致的问题。

回到正题,inode 实质上跟我们的文件控制块没有太大的差别,都是类似于下图的描述文件包含的磁盘块的结构,与我们 MOS 不同的是,为了支持更大的文件大小,可能 inode 会有多级间接块

而且相较于我们的 MOS,Linux 的 inode 中的字段更多,保存的信息也更多
// Linux 0.11 | |
struct m_inode { | |
unsigned short i_mode;/* 文件类型和属性,ls 查看的结果,比如 drwx------*/ | |
unsigned short i_uid;/* 文件宿主 id*/ | |
unsigned long i_size; | |
unsigned long i_mtime;/* 文件内容上一次变动的时间 */ | |
unsigned char i_gid;/*groupid:宿主所在的组 id*/ | |
unsigned char i_nlinks; /* 链接数:有多少个其他的文件夹链接到这里 */ | |
unsigned short i_zone[9];/* 文件映射的逻辑块号 */ | |
/* these are in memory also */ | |
struct task_struct * i_wait;/* 等待该 inode 节点的进程队列 */ | |
unsigned long i_atime;/* 文件上一次打开的时间 */ | |
unsigned long i_ctime;/* 文件的 inode 上一次变动的时间 */ | |
unsigned short i_dev;/* 设备号 */ | |
unsigned short i_num; | |
/* 多少个进程在使用这个 inode*/ | |
unsigned short i_count; | |
unsigned char i_lock;/* 互斥锁 */ | |
unsigned char i_dirt; | |
unsigned char i_pipe; | |
unsigned char i_mount; | |
unsigned char i_seek; | |
/* | |
数据是否是最新的,或者说有效的, | |
update 代表数据的有效性,dirt 代表文件是否需要回写, | |
比如写入文件的时候,a 进程写入的时候,dirt 是 1,因为需要回写到硬盘, | |
但是数据是最新的,update 是 1,这时候 b 进程读取这个文件的时候,可以从 | |
缓存里直接读取。 | |
*/ | |
unsigned char i_update; | |
}; |
Linux 系统下 FCB 储存了文件的所有信息,但索引结点下的 FCB 进行了改进,除了文件名之外的文件描述信息都放到索引节点里,这样一来该结构体大小就可以匹配磁盘块的大小,大大提升文件检索速度。如此一来 inode 模块则封装了很多东西,例如 i_op 成员定义对目录相关的操作方法列表,譬如 mkdir() 系统调用会触发 inode->i_op->mkdir() 方法,而 link () 系统调用会触发 inode->i_op->link() 方法。而 i_fop 成员则定义了对打开文件后对文件的操作方法列表,譬如 read() 系统调用会触发 inode->i_fop->read() 方法,而 write() 系统调用会触发 inode->i_fop->write() 方法
而 MOS 作为微内核操作系统,文件操作均在用户态实现,有单独的文件服务进程,对文件的操作是依靠进程间通信来完成的,这一点与上述 Linux 通过系统调用直接进行不同
# Thinking 5.4
查找代码中的相关定义,试回答一个磁盘块中最多能存储多少个文件控制块?一个目录下最多能有多少个文件?我们的文件系统支持的单个文件最大为多大?
答案
- 一个磁盘块中有
FILE2BLK= 16 个文件控制块 - 一个目录最多指向 1024 个磁盘块,因此一共目录中最多 1024*16=16384 个子文件
- 一个磁盘块大小是 4KB,使用二级索引机制,第二级是一个磁盘块,总共可以有 1024 个索引,所以单个文件是 1024 * 4KB = 4MB。
# Thinking 5.5
请思考,在满足磁盘块缓存的设计的前提下,我们实验使用的内核支持的最大磁盘大小是多少?
答案
我们的 MOS 系统相当于把整个磁盘的块和文件系统服务进程的内存空间进行了一个一一映射,因此可用映射内存大小就应当是最大硬盘大小,简单计算可以得到用于映射的内存空间为 1GB,因此最大磁盘大小也应当为 1GB
# Thinking 5.6
如果将 DISKMAX 改成 0xC0000000, 超过用户空间,我们的文件系统还能正常工作吗?为什么?
答案
理论上来说,这个地址仅仅只是虚拟地址,跟物理页没有什么关系,看起来好像是可以的。
其实并不是这样,MIPS 的地址翻译是极为特殊的,位于 kseg0 和 kseg1 等位置的虚拟地址不会经过 MMU,而是有一套单独的翻译规则,我们的文件系统是一个用户进程,对内核的高地址没有写的权限,所以不能正常工作
# Thinking 5.7
在 lab5 中, fs/fs.h 、 include/fs.h 等文件中出现了许多结构体和宏定义,写出你认为比较重要或难以理解的部分,并进行解释。
答案
// fs/fs.h | |
/* IDE disk number to look on for our file system */ | |
#define DISKNO 1 | |
#define BY2SECT 512 /* Bytes per disk sector */ | |
#define SECT2BLK (BY2BLK/BY2SECT) /* sectors to a block */ | |
/* Disk block n, when in memory, is mapped into the file system | |
* server's address space at DISKMAP+(n*BY2BLK). */ | |
#define DISKMAP 0x10000000 | |
/* Maximum disk size we can handle (1GB) */ | |
#define DISKMAX 0x40000000 |
// include/fs.h | |
// Bytes per file system block - same as page size | |
#define BY2BLK BY2PG | |
#define BIT2BLK (BY2BLK*8) | |
// Maximum size of a filename (a single path component), including null | |
#define MAXNAMELEN 128 | |
// Maximum size of a complete pathname, including null | |
#define MAXPATHLEN 1024 | |
// Number of (direct) block pointers in a File descriptor | |
#define NDIRECT 10 | |
#define NINDIRECT (BY2BLK/4) | |
#define MAXFILESIZE (NINDIRECT*BY2BLK) | |
#define BY2FILE 256 | |
// File types | |
#define FTYPE_REG 0 // Regular file | |
#define FTYPE_DIR 1 // Directory |
对关键的部分做解释, BY2SECT 表示 1 个扇区大小 512 字节, SECT2BLK 表示 1 个磁盘块是 8 个扇区, DISKMAP 和 DISKMAX 表示缓冲区地址范围为 0x10000000--0x3ffffffff,一个磁盘块大小 BY2BLK 等于一个页面大小(4KB),文件名最长为 MAXNAMELEN =128 个 char 字节, File 结构体用于索引,文件类型为文件 FTYPE_REG 或文件夹 FTYPE_DIR
前面的宏主要用于内存分配,后面的宏主要用于用户操作
然后下面有超级块的结构体 Super ,也有向文件系统服务程序发出请求的包装结构体,也有文件描述结构体(FCB)
# Thinking 5.8
阅读 user/file.c,你会发现很多函数中都会将一个 struct Fd* 型的 指针转换为 struct Filefd* 型的指针,请解释为什么这样的转换可行。
答案
这一点跟面向对象编程语言中的多态和向下转型非常类似,因此我们不妨举一个 C++ 的例子
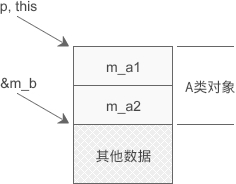
我们看到,虽然这里下面还有其它数据,但是我们的类型(这里是 struct Fd* )的大小是已知的,因此我们不关心下面是什么,只关心到 m_b 指针指向的位置,这里就是这个结构体的结束,但是如果强制转换成 struct Filefd* 型,那么其大小更大,我们就会去解析获取下面的其它数据的内容
Filefd 结构体的第一个元素就是 Fd 结构体,C 语言也能容忍强制转换操作,写代码的时候经常把一个 void* 指针变来变去的。因此直接执行这些代码没有任何问题
# Thinking 5.9
在 lab4 的实验中我们实现了极为重要的 fork 函数。那么 fork 前后的父子进程是否会共享文件描述符和定位指针呢?请在完成练习 5.8 和 5.9 的基础上编写一个程序进行验证。
答案
从 lab5-2 的课上测试来看,答案非常明显了,当然会共享文件描述符和定位指针。
课上测试的测试程序就可以作为编写的程序进行验证:
int r, fdnum, n; | |
char buf[200]; | |
fdnum = open("/newmotd", O_RDWR); | |
if ((r = fork()) == 0) { | |
n = read(fdnum, buf, 5); | |
writef("[child] buffer is \'%s\'\n", buf); | |
} else { | |
n = read(fdnum, buf, 5); | |
writef("[father] buffer is \'%s\'\n", buf); | |
} |
输出结果为:
[father] buffer is 'This ' | |
[child] buffer is 'is a ' |
可以看出父子进程有相同的文件描述符,而且定位指针的位置也被传递给了子进程
# Thinking 5.10
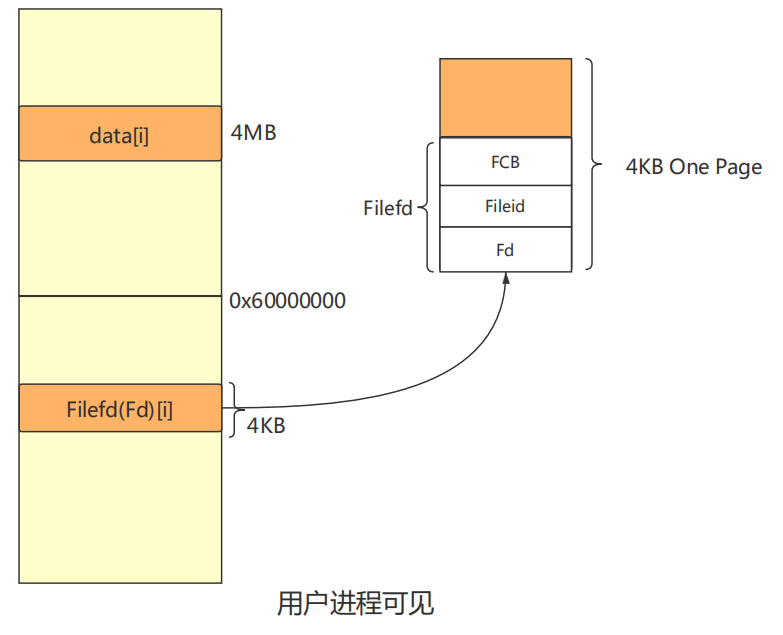
请解释 Fd , Filefd , Open 结构体及其各个域的作用。比如各个结构体会在哪些过程中被使用,是否对应磁盘上的物理实体还是单纯的内存数据等。说明形式自定,要求简洁明了,可大致勾勒出文件系统数据结构与物理实体的对应关系与设计框架。
答案
代码解读
// file descriptor | |
struct Fd { // 文件描述符,管理一个文件描述符(可以去指向打开文件),这个结构体是内存数据 | |
u_int fd_dev_id; // 设备 id | |
u_int fd_offset; // 类似于文件定位指针的作用,标记随机读写的位置 | |
u_int fd_omode; // 用户对该文件的操作权限和方式 | |
}; | |
// file descriptor + file | |
struct Filefd { // 文件描述符,描述指向已经打开的文件的文件描述符,比 Fd 多了 FCB 与 fileid,是内存数据 | |
struct Fd f_fd; // 文件描述符 记录打开的文件的部分信息 | |
u_int f_fileid; // 文件系统为打开的文件的编号 | |
struct File f_file; // 文件的描述块 | |
}; | |
// Open | |
// 定义在 fs/serve.c 中,文件系统进程使用的描述一个打开文件的结构体 | |
struct Open { // 文件系统打开文件时,用来保存打开的文件信息,使用的时候会向 FIlefd 中传递数据 | |
struct File *o_file; // 指向文件描述块的指针 | |
u_int o_fileid; // 文件系统为打开的文件的编号,不能重复(系统同时最多打开 1024 个文件) | |
int o_mode; // 用户对文件的操作权限 | |
struct Filefd *o_ff; // 文件描述符指针 | |
}; |
图示(Open 结构体保存在文件系统服务进程中,剩下两个是用户可见)
# Thinking 5.11
UML 时序图中有多种不同形式的箭头,请结合 UML 时序图的规范,解释这些不同箭头的差别,并思考我们的操作系统是如何实现对应类型的进程间通信的。
答案
操作系统课程设计与 OO 作业绝赞联动中……
言归正传,从 OO 课上(大雾),我们学到了:
同步消息,用黑三角箭头搭配黑实线表示。同步的意义:消息的发送者把进程控制传递给消息的接收者,然后暂停活动,等待消息接收者的回应消息。
返回消息,用开三角箭头搭配黑色虚线表示。返回消息和同步消息结合使用,因为异步消息不进行等待,所以不需要知道返回值。
当前 serve 执行到 ipc_recv ,通过 syscall_ipc_recv 进入使进程变成接收态 (NOT_RUNNABLE),直到它收到消息,变成 RUNNABLE,才能够被调度,从 ipc_recv 的 syscall_ipc_recv 的后面的语句开始执行,并回到 serve ,所以这个服务中的文件系统进程不会死循环,空闲时会让出 CPU 让其余进程执行
从系统 IPC 的角度来看, ipc_recv 应当是同步消息,需要等待返回值,而 ipc_send 应当是异步消息,发送后无需关心返回值可以去做自己的事情
# Thinking 5.12
阅读 serv.c/serve 函数的代码,我们注意到函数中包含了一个死循环 for (;😉 {...},为什么这段代码不会导致整个内核进入 panic 状态?
答案
该函数中有一步为 req = ipc_recv(&whom, REQVA, &perm); 它保证了在没有文件请求时,文件系统进程会一直等待下去,所以不会进入 panic 状态
事实上,文件系统进程需要永远运行下去,如果其退出了这个死循环,那绝对是致命的错误,这时内核才应该 panic
# 实验难点展示
# 难点 1:理解索引节点和数据块之间的关系
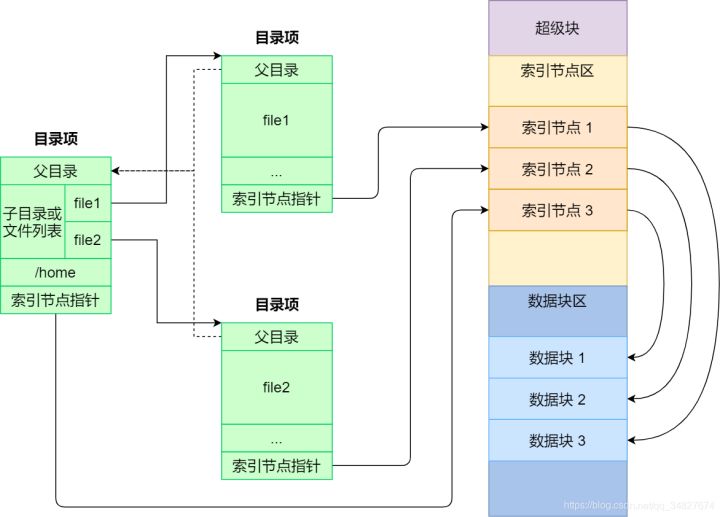
注:图片源自网络
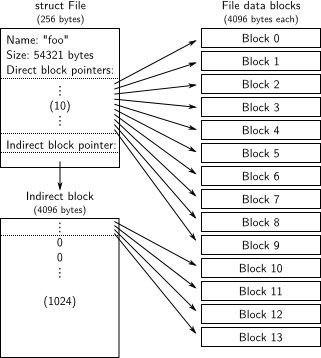
这是 MIT6.828 的 JOS 的图,我发现它们的代码跟我们的 MOS 很像诶,欸嘿嘿~
这里理解上个人认为有以下难点:
- 目录是文件,文件目录是目录,文件目录不等于目录文件
- 文件中二级指针块是从 10 开始编号的,一开始没有弄清楚这些细节,然后读代码的时候就非常费劲
- 指针指来指去很晕,自己在草稿纸上画一幅图会好一些
# 难点 2:文件系统服务进程的工作原理
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | IPC 机制
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
上图就是文件系统服务进程的工作原理
用户程序想要请求文件系统服务,需要通过进程间通信,向 serv.c 发送对应的请求结构体(定义在 fs.h )中,然后 serv.c 调用 fs.c 中的函数完成服务
文件系统的设计是一个层次化的结构,底层操作硬件,逐级向上层提供封装好的接口,在第二部分编写 fs.c 中,就无需关心磁盘读写的细节,因为这些都由 ide_read 和 ide_write 封装好了,这种设计是非常精妙的
# 体会和感想
- lab5 整体难度相较于前两个降低了许多,从我通过了两次 Extra 就可见一斑
- 但是 lab5 的设计是非常精妙的,利用一个 **C/S(服务器部分和客户机部分)** 这种当今互联网应用的常用模式,巧妙的实现微内核中的文件系统服务
- 但是我还是有些担心,相较于宏内核系统,这样的文件服务效率是否会打折扣?
- 由于时间原因,可能没有非常细致的去阅读 lab5 的代码,但是下次一定补上,其中运用的包括底层向上层暴露封装好的接口(类似于面向对象中的继承和接口设计),包括上面提到的 C/S 架构,在今后必然有很大应用,值得我们去学习