# lab-3 实验总结
# 实验思考题
# Thinking 3.1
思考 envid2env 函数:
为什么 envid2env 中需要判断 e->env_id != envid 的情况?如果没有这步判断会发生什么情况?
在判断前,我们是通过 e = &envs[ENVX(envid)]; 获取进程控制块的,这表明 e->env_id 一定与 envid 在低 10 位上相同,因为 ENVX(envid) 就是通过低 10 位的序号来访问 struct Env 结构体的。
但在 ASID 上却并不一定相同。若没有这步判断,则会查询到一个不存在的进程,导致程序出错。
究其原因,进程控制块是可以重复使用的,如果一个进程结束之后,这一个控制块会被回收再利用,这会导致出错。
# Thinking 3.2
结合 include/mmu.h 中的地址空间布局,思考 env_setup_vm 函数:
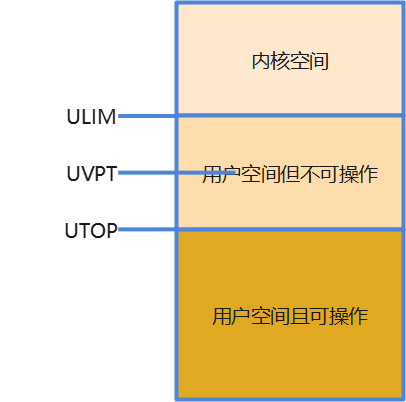
・UTOP 和 ULIM 的含义分别是什么,UTOP 和 ULIM 之间的区域与 UTOP 以下的区域相比有什么区别?
・请结合系统自映射机制解释代码中 pgdir [PDX (UVPT)]=env_cr3 的含义。
・谈谈自己对进程中物理地址和虚拟地址的理解。
UTOP = 0x7f400000 ,是为用户所能操纵的地址空间的最大值; ULIM = 0x80000000 ,是操作系统分配给用户地址空间的最大值。两者之间的区域对用户进程而言是一个只读片段,保存着用户页表 UVPT、 struct Page 、 struct Env ,显然这些都是用户程序不允许动的。UTOP 以下的区域就可以被用户程序所读写。
由自映射机制可得, pgdir[PDX(UVPT)] 就代表页表起始地址所对应的页目录项。 env_cr3 是该进程的页目录物理地址,这样即可通过页表项的虚拟地址准确找到物理地址。
- 可以理解为多个进程都可以使用 UTOP 以下的虚拟地址,但若进程间没有共享段的话,相同的虚拟地址对应于不同的物理地址。进程直接操作虚拟地址,操作系统则需要建立起不同进程的虚拟地址对物理地址的映射关系
- 而在 ULIM 之上,虚拟地址和物理地址是是直接映射的,也就是说相同的虚拟页,在 ULIM 之上会有和 ULIM 之下一模一样的一份映射存在
# Thinking 3.3
找到 user_data 这一参数的来源,思考它的作用。没有这个参数可不可以?为什么?(可以尝试说明实际的应用场景,举一个实际的库中的例子)
使用代码如下:
// 最先调用的是 load_icode 函数 | |
load_elf(binary, size, &entry_point, (void*)e, load_icode_mapper); | |
// 在调用的 load_elf 函数中,将 (void *) e 转化为 (void *) user_data,这体现在函数的定义上 | |
int load_elf(u_char *binary, int size, u_long *entry_point, void *user_data, | |
int (*map)) | |
// 也体现对 load_icode_mapper 函数的调用上 | |
map(phdr->p_vaddr, phdr->p_memsz, binary + phdr->p_offset, phdr->p_filesz, user_data) | |
// 可见最后一个参数赫然是原先的进程指针 | |
// 在函数 load_icode_mapper 中也证实了这一点 | |
struct Env *env = (struct Env *)user_data; |
如果没有这个进程指针,那么后续步骤将无法完成。
这一步操作也使用了 C 语言 void * 类型的指针可以转化成任意类型指针的特性
# Thinking 3.4
结合 load_icode_mapper 的参数以及二进制镜像的大小,考虑该函数可能会面临哪几种复制的情况?你是否都考虑到了?
复杂的情况其实教程中的图示已经给出了:

.text & .data :
- 刚开始的 va 没有页对齐,需要考虑 offset 那一段
- 中间的普通段,正常加载即可
- 最后一段,即前半部分属于
.test & .data,后半部分属于.bss,没有页对齐的情况 - 考虑长度:有没有可能
.text & .data不到一页大小呢?
.bss :
- 第一段,需要同前半段的
.test & .data段协同考虑没有页对齐的情况 - 中间的普通段正常加载
- 最后一段,即前半部分属于
.bss,后半段在需要复制的内容之外,这时需要补 0(使用 bzero) - 考虑长度:这里是不是也有可能不到一页大小?
# Thinking 3.5
思考上面这一段话,并根据自己在 lab2 中的理解,回答:
• 你认为这里的 env_tf.pc 存储的是物理地址还是虚拟地址?
・你觉得 entry_point 其值对于每个进程是否一样?该如何理解这种统一或不同?
PC 存的显然为虚拟地址,在 Lab3-2-Extra 中也利用了这一点
entry_poing 对每个进程都是一样的, *entry_point = ehdr->e_entry; 尽管不同进程其实虚拟地址一样,但加载的二进制文件、页表肯定是不一样的。每个进程起始地址统一会降低操作系统的复杂度,但在部分相同虚拟地址中的内容不同也区分了不同的进程。
# Thinking 3.6
请查阅相关资料解释,上面提到的 epc 是什么?为什么要将 env_tf.pc 设置为 epc 呢?
EPC 寄存器是 CP0 寄存器组中的一个寄存器,用来存放异常中断发生时进程正在执行的指令地址(一般该地址对应的指令还未被执行)。切换进程时,相当于施加了一个异常,这时硬件会自动帮我们把当前 PC 值保存在 EPC 寄存器中,所以下次再轮到这个进程执行时,直接从该 PC 对应地址开始执行,而不是从头执行。
考虑异常情况,如果异常(受害)指令位于延迟槽中,这时 CP0 的 Cause 寄存器 BD 位是高电平,则 EPC+4 才是受害指令的 PC 值
# Thinking 3.7
关于 TIMESTACK,请思考以下问题:
• 操作系统在何时将什么内容存到了 TIMESTACK 区域
• TIMESTACK 和 env_asm.S 中所定义的 KERNEL_SP 的含义有何不同
在 env_destory 和 env_run 函数中利用到了 TIMESTACK 区域,前者将自身进程栈中存放的内容赋值到该区域,后者将该区域的内容复制到当前进程的状态中,以便切换到下一进程。
//在stackframe.S中,异常处理会将栈指针置于TIMESTACK处
//这样就能在发生异常时将当前进程状态存入TIMESTACK
//env_destory销毁本身进程时也是如此
li sp, 0x82000000
lw sp, KERNEL_SP
我们结合 Lab4 的知识,甚至可以认为 TIMESTACK 就是系统进程切换时使用的栈,保存了内核态上下文,而 KERNEL_SP 保存了 TRAPFRAME 是用户态陷入内核态(可以是中断,可以是系统调用)保存的上下文
# Thinking 3.8
试找出上述 5 个异常处理函数的具体实现位置。
handle_int 函数在 genex.S 文件中, handle_sys 函数在 syscall.S 文件中。另外三个函数 handle_reserved 、 handle_tlb 、 handle_mod 都在 genex.S 文件中,没有直接明确的函数名,是靠拼接而成,具体声明位于最后,但定义在最开始。
# Thinking 3.9
阅读 kclock_asm.S 和 genex.S 两个文件,并尝试说出 set_timer 和 timer_irq 函数中每行汇编代码的作用
LEAF(set_timer)
//对定时器的初始化
li t0, 0xc8
sb t0, 0xb5000100 //向0xb5000100地址写入0xc8
sw sp, KERNEL_SP //保存当前栈指针
//把CP0_STATUS第12位和第0位置1,允许4号中断,并表示开启了中断,禁止再次响应中断
setup_c0_status STATUS_CU0|0x1001 0
jr ra //函数返回
nop //延迟槽
END(set_timer)
timer_irq:
sb zero, 0xb5000110 //向地址0xb5000110写入0
1:
j sched_yield //进入进程调度函数,调度下一个进程
nop //延迟槽
j ret_from_exception //跳转到ret_from_exception函数,执行rfe指令,从异常中返回
nop
# Thinking 3.10
阅读相关代码,思考操作系统是怎么根据时钟周期切换进程的。
进程装在两个队列中,一次运行一个进程。定时器周期性产生中断,使得当前进程被迫停止,通过执行 sched_yield 函数,来进行进程的调度。(这一部分在 kclock_asm.S 的 time_irq 中)
若该进程时间片还未用完,则可用时间片数量-1,否则会切换到下一个进程,保存上下文。并将原来的进程送到另一个队列的末尾,若进程不处于 RUNNABLE 状态,则会进行其他处理。(这一部分在 sched.c 的 sched_yield 中)
值得注意的是为什么这里需要使用两个链表来保存调度进程呢?考虑如果当前没有任何可运行的进程时,如果使用一个队列加入队尾,那么就会无限循环下去,使用两个队列就可以在此时报错 panic("no runnable env");
# 实验难点图示
本次实验总体来说,第一部分相较于第二部分难度更大
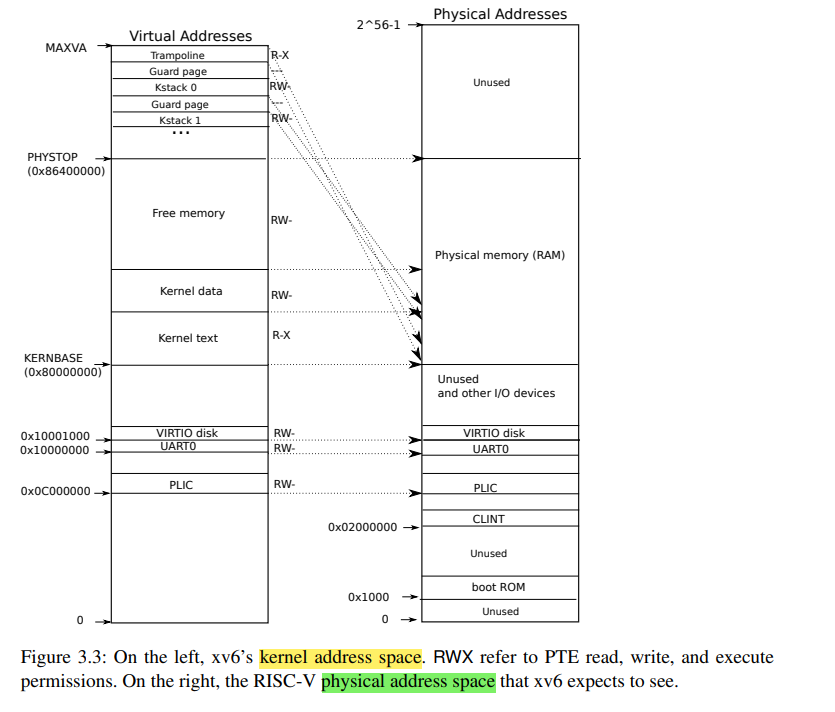
# 内存空间分布
- 搞清楚用户空间最大使用内存大小为 2GB
- 发现 ULIM 下面的页其实在 ULIM 上面有一份直接映射(其实存在了两次)
- 总结:ULIM 上面其实是物理地址空间,ULIM 下面其实是用户虚拟地址空间,两者合在一起是内核虚拟地址空间,搞清楚这些之间的区别,Lab2 和 Lab3 都豁然开朗
# 进程映像的加载
graph LR; | |
function1("load_icode<br />分配内存<br />装入内存") --调用.-> function2(load_elf<br />解析ELF<br />将ELF复制进内存) --调用.-> function3(load_icode_mapper) |
load_icode_mapper 是较难补全的,这主要是实现的难度,而其它的代码主要是理解的难度
这段代码的补全难在提示很少,很难做到考虑完全所有的情况
这段学习是可以结合 Lab1 中 ELF 文件的相关知识
# 中断处理过程
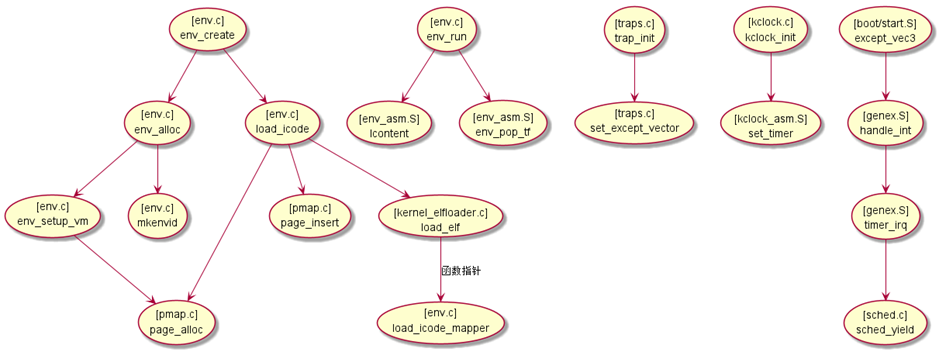
这一部分难在大部分处理由汇编语言完成,因此很难梳理执行过程,这里我找到了网络上的一张图片,讲了进程的加载和调度过程
难点在于汇编语法不熟悉,汇编语言里使用了大量的宏和 .set 设置,这些都没有在计组课程中详细了解,因此需要边学边读,难度不小,但是考虑到这次 Lab3-2-Extra 就考察了异常处理的内容,因此可见这一部分对课程整体来说还是非常重要的,这在 Lab4 系统调用中也是重中之重,是基础内容
# 进程调度
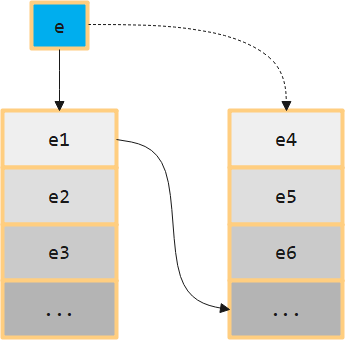
感觉这部分实验反而没有理论课难,理论课程中讲了许多调度算法,但是我们实现时仅仅实现了最简单的一种,上面是网络上讲时间片轮转调度中画的比较好看的一幅图,可以发现它也使用了双队列调度,首先在一个队列中寻找,如果进程不在可运行状态那么就把它加到另一个队列的末尾,否则就运行,并把这个进程加到另一个队列的末尾
不过这里还是有疑问,在思考题解答中也提到过,为什么这里需要两个队列呢?
# 体会与感想
首先对实验有一点建议,就是代码的缩进风格希望能够统一,实验中的某些 C 语言代码的风格是不一致的,这非常不利于阅读,我认为作为课程实验的代码,至少应当制定一定的代码规范,包括何时换行,大括号放在哪里,就更不必说汇编代码了,更是乱七八糟,根本没有缩进,有的 nop 前面没有 tab,后面又有了 tab,不仔细阅读,根本搞不明白哪里是宏,哪里是代码,函数从哪里开始,从哪里结束。这几天我去做了 MIT 的 xv6 系统的实验,代码风格统一,命名规范,甚至开启了将所有警告视作错误的 gcc 编译选项(就是代码里面甚至没有警告),
而且封装好了汇编函数,所以不需要写汇编,我觉得这是值得我们借鉴的(这条有没有被看见就另说了)Lab2 非常重要,理解了内存空间,操作系统实验才能继续下去,个人非常希望课程组能在之后的课程中 Lab2 至少画出下图这样详细的图,可以帮助我们理解用户虚拟地址空间、内核虚拟地址空间、物理地址空间的关系,页表页目录进程控制块究竟在上述三个空间中存放在哪里,每一部分空间对应什么,我觉得有助于我们理解,
mmu.h里面的那幅图太抽象了......![image-20220513203449446]()
汇编语言非常重要,有必要在一开始提示去复习计组的相关内容!这次上机的 Extra 就彰显了汇编的重要性(虽然用 C 也能做,但是汇编更加符合直觉吧~)
我不是很会使用 gxemul 的调试功能,所以一旦出了 Bug 就是虚空调试,我觉得这一点需要今后加强学习,否则课上考试不会用这么好的运气,可能会寄~