
# lab-2 实验总结
# 思考题解答
Thinking 2.1
请你根据上述说明,回答问题:
在我们编写的程序中,指针变量中存储的地址是虚拟地址还是物理地址?
MIPS 汇编程序中 lw, sw 使用的是虚拟地址还是物理地址?
【答案】
指针变量中存储的是虚拟地址,因为程序需要编译成机器码由 CPU 发出访存请求,而 CPU 只能发出虚拟地址访问请求
MIPS 汇编程序中 lw, sw 使用的是也是虚拟地址,因为本质上还是 CPU 访存
Thinking 2.2
- 请从可重用性的角度,阐述用宏来实现链表的好处。
- 请你查看实验环境中的
/usr/include/sys/queue.h,了解其中单向链表与循环链表的实现,比较它们与本实验中使用的双向链表,分析三者在插入与删除操作上的性能差异。
【答案】
正如指导书中所说,C++ 和 Java 这些高级语言中有一种特性叫做泛型,可以通过实现模板类的方法对于不同的数据类型使用相同的代码
例如,C++ 中我们可以用下面的代码来实现一个栈
template <typename T>
class Stack {
T data[1000];
int top;
public:
void push(T i);
T pop();
}
那么在定义的时候对于不同的数据类型,我们只需要定义
Stack<int> stack1;
Stack<double> stack2;
Stack<char> stack3;
就可以对应不同类型的栈,这就实现了代码复用
在 OS 实验中通过使用宏,我们也实现了代码复用,对于管理物理页面的 Pages 结构体,和后面 lab3 中可能需要管理用户进程的 Envs 结构体,我们无需重复相似的代码,使用列表宏,可以将两者分别串联成链表,这就是使用宏的好处
值得一提的是,C++ 的模板类是编译器在编译中替换的,对于不同的类型,编译器会新增加相应类型的代码,而我们实验使用宏,替换则是在预处理阶段实现的
在实验环境中查看 Linux 系统的内核源码,发现实验中的双向链表看上去是直接来自内核源码,下面比较单向链表、循环链表和双向链表
** 插入操作:** 单向链表插入操作十分简单,两行代码,双向链表插入操作一般运行四行代码,需要额外判断是否 next 指向了 NULL,循环链表与双向链表运行代码量基本相等,需额外判断是否 next 指向了头指针。特别的是,插入到头结点对三种链表而言性能相似,单向链表与双向链表插入到尾结点均要遍历完整个链表
** 删除操作:** 单向链表的删除操作复杂度为 O (n),因为需要靠循环才能找到上一个链表节点的位置,双向链表及循环链表的删除操作与插入性能相近,也还是需要额外判断 NULL 或 HEAD。删除头结点对三种链表而言性能相似,而单向链表与双向链表删除尾结点还是要遍历所有节点
Thinking 2.3
请阅读 include/queue.h 以及 include/pmap.h , 将 Page_list 的结构梳理清楚,选择正确的展开结构
【答案】
本题选项略,展开后很容易看出选 C
Thinking 2.4
请你寻找上述两个 boot_* 函数在何处被调用
【答案】
boot_map_segment() 函数在 mips_vm_init() 中被调用了两次:

容易看出其目的是将 pages 结构体映射到虚拟地址 UPAGES 位置,将 envs 结构体映射到虚拟地址 UENVS 位置,这一映射也符合 mmu.h 中内存分布图示
boot_pgdir_walk() 函数在 boot_map_segment() 中被调用:

可以看出其目的是为了寻找虚拟地址 va+i 所对应的页表项,并返回对应项的虚拟地址, boot_map_segment() 中修改这一项的值从而建立映射
**Thinking 2.5 **
请你思考下述两个问题:
- 请阅读上面有关 R3000-TLB 的叙述,从虚拟内存的实现角度,阐述 ASID 的必要性
- 请阅读《IDT R30xx Family Software Reference Manual》的 Chapter 6,结合 ASID 段的位数,说明 R3000 中可容纳不同的地址空间的最大数量
【答案】
**ASID 的必要性:** 同一虚拟地址在不同地址空间中通常映射到不同物理地址,ASID 可以判断是在哪个地址空间。简要打比方来说,可能有多个进程都用到了这个虚拟地址,但该虚拟地址对应的数据大概率是不一样的,则因此指向的是不同物理地址,为了防止不同进程通过页表的错误数据访问到了错误的物理地址,因此添加了 ASID 这一标志位,这是对地址空间的一种保护。
** 可容纳不同地址空间的最大数量:**64 个,参考原文如下:
Instead, the OS assigns a 6-bit unique code to each task’s distinct address space. Since the ASID is only 6 bits long, OS software does have to lend a hand if there are ever more than 64 address spaces in concurrent use; but it probably won’t happen too often.
**Thinking 2.6 **
请你完成如下三个任务:
- tlb_invalidate 和 tlb_out 的调用关系是怎样的?
- 请用一句话概括 tlb_invalidate 的作用
- 逐行解释 tlb_out 中的汇编代码
【答案】
tlb_invalidate 调用 tlb_out
调用 tlb_invalidate 可以将该地址空间的虚拟地址对应的表项清除出去,一般用于这个虚拟空间引用次数为 0 时释放 TLB 空间
LEAF(tlb_out)
//1: j 1b
nop
mfc0 k1,CP0_ENTRYHI //保存ENTRIHI原有值
mtc0 a0,CP0_ENTRYHI //将传进来的参数放进ENTRYHI中
nop
tlbp //检测ENTRYHI中的虚拟地址在tlb中是否有对应项
nop
nop
nop
nop
mfc0 k0,CP0_INDEX //INDEX可以用来判断是否命中
bltz k0,NOFOUND //若k0最高位为1,即小于零,则表示未命中,则跳转的NOFOUND位置
nop
mtc0 zero,CP0_ENTRYHI //否则,将ENTRYHI清零
mtc0 zero,CP0_ENTRYLO0 //将ENTRYLO清零
nop
tlbwi //将清零后的两寄存器值写入到对应TLB项中, 相当于删除原有的TLB项
NOFOUND:
mtc0 k1,CP0_ENTRYHI //将原来的ENTRYHI恢复
j ra //返回查询到的地址
nop
END(tlb_out)
Thinking 2.7
在现代的 64 位系统中,提供了 64 位的字长,但实际上不是 64 位 ** 页 ****** 式存储系统。假设在 64 位系统中采用三级页表机制,页面大小 4 KB。由于 64 位系统中字长为 8 B,且页目录也占用一页,因此页目录中有 512 个页目录项,因此每级页表都需要 9 位。因此在 64 位系统下,总共需要 3 × 9 + 12 = 39 位就可以实现三级页表机制,并不需要 64 位。现考虑上述 39 位的三级页式存储系统,虚拟地址空间为 512 GB,若记三级页表的基地址为 PTbase ,请你计算:
三级页表页目录的基地址
映射到页目录自身的页目录项 (自映射)
【答案】
不妨记页表基地址 (page table) 为 PTbase
页中间目录基地址 (page middle directory) PMDbase : (PTbase >> 12) << 3 + PTbase
页全局目录 (page global directory) PGDbase : (PTbase >> 21) << 3 + PMDbase (三级页表页目录的基地址)
页全局目录项(page global directory entry) PGDE : (PTbase >> 30) << 3 + PGDbase (自映射)
Thinking 2.8
任选下述二者之一回答:
- 简单了解并叙述 X86 体系结构中的内存管理机制,比较 X86 和 MIPS 在内存管理上的区别。
- 简单了解并叙述 RISC-V 中的内存管理机制,比较 RISC-V 与 MIPS 在内存管理上的区别。
【答案】
X86 体系结构中,以经典的 80386 处理器为例,下面内容整理自清华大学 ucore 操作系统实验指导书
80386 是 32 位的处理器,即可以寻址的物理内存地址空间为 字节。为更好理解面向 80386 处理器的 ucore 操作系统,需要用到三个地址空间的概念:物理地址、线性地址和逻辑地址。物理内存地址空间是处理器提交到总线上用于访问计算机系统中的内存和外设的最终地址。一个计算机系统中只有一个物理地址空间。线性地址空间是 80386 处理器通过段(Segment)机制控制下的形成的地址空间。在操作系统的管理下,每个运行的应用程序有相对独立的一个或多个内存空间段,每个段有各自的起始地址和长度属性,大小不固定,这样可让多个运行的应用程序之间相互隔离,实现对地址空间的保护。
在操作系统完成对 80386 处理器段机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立全局描述符表,完成虚拟地址与线性地址的映射关系)后,80386 处理器的段管理功能单元负责把虚拟地址转换成线性地址,在没有页机制启动的情况下,这个线性地址就是物理地址。
相对而言,段机制对大量应用程序分散地使用大内存的支持能力较弱。所以 Intel 公司又加入了页机制,每个页的大小是固定的(一般为 4KB),也可完成对内存单元的安全保护,隔离,且可有效支持大量应用程序分散地使用大内存的情况。
在操作系统完成对 80386 处理器页机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立页表,完成虚拟地址与线性地址的映射关系)后,应用程序看到的逻辑地址先被处理器中的段管理功能单元转换为线性地址,然后再通过 80386 处理器中的页管理功能单元把线性地址转换成物理地址。
显然,页机制和段机制有一定程度的功能重复,但 Intel 公司为了向下兼容等目标,使得这两者一直共存。
上述三种地址的关系如下:
- 分段机制启动、分页机制未启动:逻辑地址 ---> 段机制处理 ---> 线性地址 = 物理地址
- 分段机制和分页机制都启动:逻辑地址 ---> 段机制处理 ---> 线性地址 ---> 页机制处理 ---> 物理地址
与我校的 MOS 操作系统实验相比,MIPS 的内存管理更为简单,仅有页机制,没有段机制处理
# 实验难点展示
# 填写链表宏

作为实验的第一部分,我觉得这一部分对于我们的编程能力是一大挑战,因为在学习 C 语言的过程中,我们对宏的学习一般都是浅尝辄止,并没有深入系统的进行了解,就像上一个 lab 中对于可变长参数列表的理解一样,这都属于语言层面的障碍
同时在数据结构课程中,我们实现的链表都是单一类型的,而这一次我们通过宏来实现了泛型,这是实验中需要转变的一个思想,在链表宏中,我们把数据和连接项分开,数据就是 Page 结构体中 ref 等变量,而连接项 pp_link 是由 LIST_ENTRY 宏指定的,对于任何一种数据结构组成链表都相同的 le_next 和 le_prev
除此之外,填写链表的插入和删除都是数据结构课程中老生常谈的话题,难度不是很大。在实验的一个任务中,我们需要将元素插入链表的尾部,解答本题使用的利用 elm 中的 elm->field.le_next 指针做跳板,把 elm 跳到链表尾的方法非常的巧妙,是一个难点
关于链表宏的疑惑:为什么 le_prev 指向的不是上一个节点,而是上一个节点的 pp_link 中的 le_next ?这样难道不就很难去访问上一个节点了吗,是否背离了使用双向链表的初衷?(当然这样删除和插入还是相当方便的,为什么不指向上一个节点,让访问上一个节点也变得这样方便呢?)
# 物理内存管理
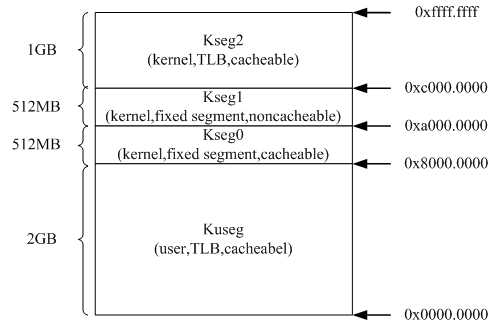

物理内存管理部分,我认为最大的难点在于混淆了物理内存和虚拟内存的位置。在我的印象中,我认为物理内存应当是像虚拟内存那样整齐的分层的一块一块排列好的,然后对应的填进去就可以了,简单来说也就是物理内存也应当是分块的,排列成像上图那样。
但是实际上不是这样,理解物理内存分配要从理解 extern char end[] 这句话开始,我们在链接脚本中规定了 end=0x80400000 ,就像上图中的虚拟内存图中 end 的位置一样,然后物理内存对于操作系统而言就仿佛像是一根长长的木棍,它就是 end 数组,然后当我们需要的时候(比如在 alloc 函数中),我们需要多少,就从这个木棍中切下来多少,然后 freemem 这个变量始终指向木棍开始的位置,在一开始操作系统尚未建立分页的时候,我们就是这样从木棍上切下来了 pages 结构体数组和 env 结构体数组的内存空间,还有内核的页目录的内存空间,以及建立映射时可能需要的页表的内存空间
理解完这个以后,对物理内存的其它部分就不难理解了
# 虚拟内存管理
这一部分最难理解的就是自映射部分...... 理论课上讲的差不多了,仔细想想还是不难理解的,不能说是难点
用户进程拥有属于自己的页表,就存在上图中的 UVPT 的位置,这个我一开始是不知道的,也算是理解上的难点,即用户页表和内核页表是分开的,显然用户页表连续,因此可以进行自映射,但是内核页表在上文中分析过了,是需要的时候就切一块,因此不连续,也不知道映射到了虚拟内存的什么位置,因此不会有自映射
# 指导书反馈
应该也有很多同学在讨论区和群里提到这个问题了,当在 pgdir_walk 中分配了一页后,需要将其对应的页控制块的引用加 1,但是给出的框架中没有提示去补这行代码,如下图所示:
