# P5 课下项目:流水线 CPU 设计(1)
阅读本文或许可以给您完成 P5 课下任务提供些许帮助,但是绝对不能让你完全搭出 P5
这篇文章只是讲了我个人对于流水线的一些理解,剩下的可以参考其他大佬的代码学习
如果我也能发 D-Mail 的话,我要告诉一周前的自己 bonall 指令是无条件链接,然后世界线就会切换到我上周就过了 P5 的 世界线了
# 总体设计概述
要求实现的指令集为 MIPS-lite2 ,即 addu,subu,ori,lw,sw,beq, jal,jr,lui,nop
整体结构如下图所示
# 命名规范
由于到了 P5 流水线,导线和元件实在太多了,所以用特定的名称约定便于编码:
- 对于元件的文件命名,均为
流水线层级_元件英文简称,例如D_GRF.v,E_ALU.v等,实例化时命名为_小写英文名,例如_alu,_grf等 - 对于流水线寄存器文件命名为
两边的流水线层级_REG,例如FD_REG.v,DE_REG.v,实例化时命名为_小写英文名,例如_fd_reg - 每一级的控制信号和临时的
wire均以本级的名称开头,如E_ALUOp,M_DMOp等 - 在流水线中参与流水的信息遵从以下约定(以 D 级为例)
PC和Instr命名以流水线层级开头,如D_PC,D_Instr- 寄存器地址分别为
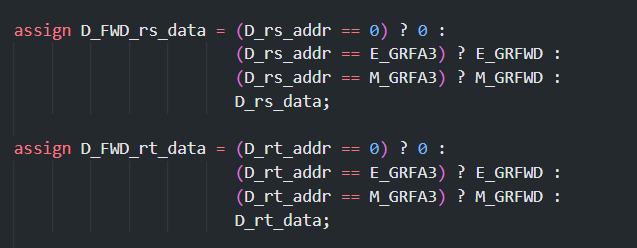
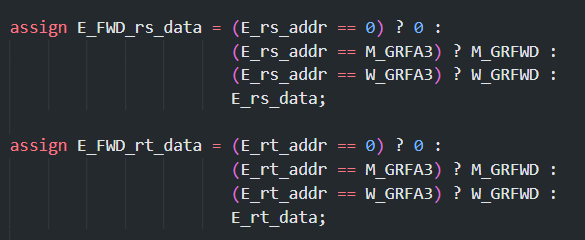
D_rs_addr,D_rt_addr,读出数据为D_rs_data,D_rt_data - 转发得到的寄存器数据(直接读取也视为一种转发)记作
D_FWD_rs_data,D_FWD_rt_data - 即将写入的寄存器地址为
E_GRFA3,即将写入的数据记作E_GRFWD,选择信号为E_GRFWDSel
# 一些搭建要点
首先是译码,我参考了一些大佬的架构后,采用了分布式译码,CTRL 在每一级都会进行译码,即只写一个 control.v 模块,然后实例化四次,每一次都根据 Instr 信号译码得到当前流水线层级需要的控制信号和别的转发需要的乱七八糟的东西(转发后面再讲)
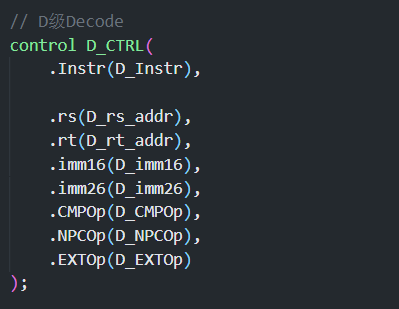
# D 级 (Decode / 译码)
# E 级 (Execute / 执行)

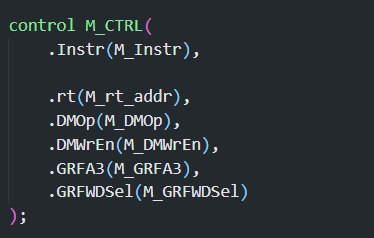
# M 级 (Memory / 储存)
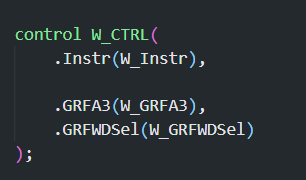
# W 级 (Write / 回写)
可以确定的是,我们的 Instr 和 PC 信号必须跟着流水线一起传递, Instr 是译码需要, PC 是评测机要求输出 PC 的值
流水线复杂的一点在于,它有 FDEMW 五个层级,每一个层级都有很多信号需要处理,但是每一级都只是组合逻辑(不考虑 P6 的乘除槽),因此我们首先要搞清楚的是每一级都需要什么数据,每一级又向后输出什么数据,然后只需要考虑每个层级里面的逻辑就行了
下面将按照流水线层级逐一分析各个单元
# F 级 (Fetch / 取指令)
- 本级的输入是来自 D 级的
NPC - 本级的输出是
F_PC和F_Instr,两者需要参与流水线流水
# IFU(取指单元)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| NPC[31:0] | 输入 | 待写入 PC 的指令地址 |
| clk | 输入 | 时钟信号 |
| reset | 输入 | 同步复位信号 |
| PC_WrEn | 输入 | PC 的写使能 |
| PC | 输出 | 当前指令地址 |
| Instr[31:0] | 输出 | 32 位的指令值 |
# D 级 (Decode / 译码)
- 本级的输入是来自 F 级的
PC和Instr - 输出是
D_rs_data(从 GPR 里面读的 rs 的值),D_rt_data(从 GPR 里面读的 rt 的值),D_ext32(16 位立即数扩展后的值),D_PC和D_Instr,还有输出到 F 级的NPC - 其他的信号像 D_rs_addr 都可以从 control 中译码得到
# FD_REG(F/D 级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | 输入 | 时钟信号 |
| reset | 输入 | 同步复位信号 |
| flush | 输入 | 寄存器刷新信号(阻塞时使用) |
| F_PC | 输入 | F 级 PC 的指令地址 |
| F_Instr[31:0] | 输入 | 时钟信号 |
| D_PC | 输出 | D 级 PC 的指令地址 |
| D_Instr[31:0] | 输出 | 32 位的指令值 |
# D_GRF(寄存器堆)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| A1[4:0] | 输入 | 5 位地址输入信号,将其储存的数据读出到 RD1 |
| A2[4:0] | 输入 | 5 位地址输入信号,将其储存的数据读出到 RD2 |
| A3[4:0] | 输入 | 5 位地址输入信号,将其作为写入数据的目标寄存器 |
| RD1[31:0] | 输出 | 输出 A1 指定的寄存器中的 32 位数据 |
| RD2[31:0] | 输出 | 输出 A2 指定的寄存器中的 32 位数据 |
| WD[31:0] | 输入 | 32 位数据输入信号 |
| clk | 输入 | 时钟信号 |
| reset | 输入 | 异步复位信号,将 32 个寄存器中的数据清零;1:复位;0:无效 |
- 这次删去了
GRFWrEn写使能信号,因为如果我们不写寄存器,可以把GRFA3设为 0,就相当于不写寄存器了
1. D_GRFA3
直接给出待写入寄存器的地址,弃用了在 P4 中利用 GRFA3Sel 进行选择的设计,这是因为 P5 采用分布式译码,每一级都需要 GRFA3 的信息,因此在 CTRL 里面直接集成了
2. D_GRFWDSel
| 控制信号值 | 功能 |
|---|---|
WDSel_dmrd | 选择写入寄存器的数据来自 DM |
WDSel_aluans | 选择写入寄存器的数据来自 ALU 运算结果 |
WDSel_pc8 | 选择写入寄存器的数据为当前流水线层级中的 PC+8 |
# D_EXT(位扩展)
将 16 位二进制数进行零扩展或符号扩展到 32 位
| 控制信号值 | 功能 |
|---|---|
EXT_unsign | 零扩展 |
EXT_sign | 符号扩展 |
# D_CMP(比较器)
把原来 ALU 中比较值是否相等的运算移到了 CMP 里面,去指导 beq 这一类型的指令是否跳转
控制信号目前只有 CMP_beq ,未来可以扩展
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| rs[31:0] | 输入 | 处理完转发后 $rs 寄存器的值 |
| rt[31:0] | 输入 | 处理完转发后 $rt 寄存器的值 |
| CMPOp[2:0] | 输入 | 控制信号 |
| b_jump | 输出 | 指示是否跳转,输入 NPC ,未来可以添加 bltzal 指令 |
# D_NPC(次地址计算单元)
把 beq 是否执行的判断交给了 CMP ,直接根据输入信号 jump 判断是否跳转
其实 NPC 横跨了 F 级和 D 级两级,因为同时会输入 F_PC 和 D_PC ,前者正常跳转 F_PC+4 用,后者则用于流水 PC 值,后面转发 PC+8 的时候用
这次我们弃用了 P4 中直接输出 PC+4 的设计,转而让 PC 信号参与流水,在需要转发时计算 PC+8
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| F_PC[31:0] | 输入 | 32 位输入当前 F 级地址 |
| D_PC[31:0] | 输入 | 32 位输入当前 D 级地址 |
| b_jump | 输入 | 指示 b 类型指令是否跳转 |
| NPCOp[1:0] | 输入 | 控制信号 |
| RSS[31:0] | 输入 | 处理完转发后 $rs 寄存器保存的 32 位地址 |
| NPC[31:0] | 输出 | 32 位输出次地址 |
# 控制信号说明
| 控制信号值 | 功能 |
|---|---|
NPC_pc4 | NPC=PC+4 |
NPC_b | 执行 beq 等 b 类指令 |
NPC_j_jal | 执行 j , jal 指令 |
NPC_jalr_jr | 执行 jalr , jr 指令 |
# E 级 (Execute / 执行)
- 输入
D_PC,D_Instr,D_ext32,此外上一级的$rs和$rt的值也要参与流水,即D_FWD_rs,D_FWD_rt需要参与流水,这是由于指令序列sw, nop, addu的存在,sw在 M 级需要使用$rt的数据,但是在 E 级不会再进行转发(因为在 D 级已经转发过了),因此需要让正确的$rt值参与流水 - 输出
E_PC,E_Instr,E_ext32,E_rs_data,E_rt_data,ALU需要这些信息
# DE_REG(D/E 级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | 输入 | 时钟信号 |
| reset | 输入 | 同步复位信号 |
| flush | 输入 | 寄存器刷新信号(阻塞时使用) |
| D_PC[31:0] | 输入 | D 级 PC 的指令地址 |
| D_Instr[31:0] | 输入 | 32 位的指令值 |
| D_ext32[31:0] | 输出 | 16 位立即数经 EXT 扩展的结果 |
| D_rs_data[31:0] | 输出 | 32 位的寄存器数据 |
| D_rt_data[31:0] | 输出 | 32 位的寄存器数据 |
| E_PC[31:0] | 输入 | E 级 PC 的指令地址 |
| E_Instr[31:0] | 输入 | 32 位的指令值 |
| E_ext32[31:0] | 输出 | 16 位立即数经 EXT 扩展的结果 |
| E_rs_data[31:0] | 输出 | 32 位的寄存器数据 |
| E_rt_data[31:0] | 输出 | 32 位的寄存器数据 |
# E_ALU(算术逻辑单元)
- 相比于 P4,ALU 做了很大的变动,添加了
ALUASel信号选择 A 运算数的来源,这是为了便于扩展sll和sllv类指令的原因取消了shamt信号,shamt信号从ALUBSel中选择进入ALU中
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| A[31:0] | 输入 | 32 位输入运算数 A |
| B[31:0] | 输入 | 32 位输入运算数 B |
| ALUOp[4:0] | 输入 | 控制信号 |
| C[31:0] | 输出 | 32 位输出运算结果 |
1. ALUOp
| 控制信号值 | 功能 |
|---|---|
ALU_add | 执行加法运算 |
ALU_sub | 执行减法运算 |
ALU_or | 执行逻辑或运算 |
ALU_lui | 执行 lui 指令 |
2. ALUASel
| 控制信号值 | 功能 |
|---|---|
ASel_rt | 对于 sll 和 sllv 等移位指令,选择 $rt 的值 |
ASel_rs | 对于其他大部分运算指令,采用 $rs 的值 |
3. ALUBSel
| 控制信号值 | 功能 |
|---|---|
BSel_rt | 选择处理完转发后 $rt 寄存器中的值进行运算 |
BSel_imm | 选择立即数进行运算 |
BSel_shamt | 使用 {27'b0, E_ALUshamt} 得到 32 为扩展移位数 |
BSel_rs | 考虑到 sllv 指令要求可变的位移数,这里可以选择 {27'b0, E_FWD_rs_data[4:0]} ,即 $rs 寄存器中的数据作为移位数 |
# M 级 (Memory / 储存)
- 输入
E_PC,E_Instr,此外E_ALUAns,E_ext32也需要输入,这是因为ALUAns是待写入或读取的内存地址,另外,上一级的 rt 值需要进入 M 级,因此还需要输入E_FWD_rt,这是因为sw指令会向内存中写入$rt的数据 - 输出
M_PC,M_Instr,M_ALUAns,M_DMRD
# EM_REG(E/M 级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | 输入 | 时钟信号 |
| reset | 输入 | 同步复位信号 |
| flush | 输入 | 寄存器刷新信号(阻塞时使用) |
| E_PC[31:0] | 输入 | E 级 PC 的指令地址 |
| E_Instr[31:0] | 输入 | 32 位的指令值 |
| E_ext32[31:0] | 输入 | 16 位立即数经 EXT 扩展的结果 |
| E_rt_data[31:0] | 输入 | 32 位的寄存器数据 |
| E_ALUAns[31:0] | 输入 | 32 位的 ALU 运算结果 |
| M_PC[31:0] | 输出 | M 级 PC 的指令地址 |
| M_Instr[31:0] | 输出 | 32 位的指令值 |
| M_ext32[31:0] | 输出 | 16 位立即数经 EXT 扩展的结果 |
| M_ALUAns[31:0] | 输出 | 32 位的 ALU 运算结果 |
| M_rt_data[31:0] | 输出 | 32 位的寄存器数据 |
# M_DM(数据储存器)
- 与 P4 基本相同
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| Addr[31:0] | 输入 | 待操作的内存地址 |
| WD[31:0] | 输入 | 待写入内存的值 |
| clk | 输入 | 时钟信号 |
| reset | 输入 | 异步复位信号 |
| DMWrEn | 输入 | 写使能信号;1:写入有效;0:写入无效 |
| DMOp[2:0] | 输入 | 控制信号 |
| RD[31:0] | 输出 | 输入地址指向的内存中储存的值 |
| 控制信号值 | 功能 | |
| ---------- | -------------------------------------------- | |
DM_w | 对应 lw 和 sw 指令,写入或读取整个字 | |
DM_h | (保留)对应 lh 和 sh 指令,写入或读取半字 | |
DM_b | (保留)对应 lb 和 sb 指令,写入或读取整个字 | |
DM_hu | (保留)对应 lhu 指令 | |
DM_bu | (保留)对应 lbu 指令 |
# W 级 (Write / 回写)
- W 级事实上与 D 级重合了,但是仍然需要处理向 E,M 级的转发
# MW_REG(M/W 级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | 输入 | 时钟信号 |
| reset | 输入 | 同步复位信号 |
| flush | 输入 | 寄存器刷新信号(阻塞时使用) |
| M_PC[31:0] | 输入 | M 级 PC 的指令地址 |
| M_Instr[31:0] | 输入 | 32 位的指令值 |
| M_DMRD[31:0] | 输入 | 从内存中读取的值 |
| M_ALUAns[31:0] | 输入 | 32 位的 ALU 运算结果 |
| W_PC[31:0] | 输出 | W 级 PC 的指令地址 |
| W_Instr[31:0] | 输出 | 32 位的指令值 |
| W_DMRD[31:0] | 输出 | 从内存中读取的值 |
| W_ALUAns[31:0] | 输出 | 32 位的 ALU 运算结果 |
其实我们发现,每一级的流水线寄存器是承上启下的作用,搞清楚流水线寄存器怎么写,就明白了每一级需要输入什么数据,又需要输出什么数据,每一级内部的东西跟 P4 比其实没有啥变化
变化最大的需要关注 NPC ,它处于 D 级,但同时接受 F 和 D 级的输入,而且输出 NPC 是直接回写的 F 级的,比较麻烦
D 级的元件最多,非常复杂,可以尝试把他们分成运算区(EXT, GPR)、跳转区(CMP, NPC)考虑,这样会容易一点
# 冲突处理方法
# 转发
为什么要转发?简单讲就是如果我用的寄存器里面的值,现在还没有写到寄存器里面,但是已经被算出来了,这个时候就需要算出来的那条指令告诉我他算出来了啥,我就不用寄存器里面的值了,这就是转发
对于转发,直接采用 AT 法 + 暴力转发,首先要搞明白转发到哪,转发什么
对于每一个流水线层级,我们要能够确定当前这一级正在执行的指令要写什么数据,向哪里写,因此就要维护 GRFWD (解决转发啥)和 GRFA3 (解决转发到哪)这两个值,我们转发需要去关注的也就是这两个数据,这些信号都可以从 Control 里面译码读出来
简单来说就是,我们需要在每一级都知道本级需要从哪读数据,要写到哪,要写啥,现在不知道没事,总之在这条指令从流水线消失之前,我们肯定知道,并且可以根据这些再经过判断做转发
需要用转发数据的地方参考下面这张图的红色部分,图里面的 MDU 是乘除槽,P5 不用做(图片来源:Coekjan)

在每一个需要用转发数据的地方,我们去比较要用的数据的 GPR 地址和前面正在维护的要写的 GRFA3 的地址,如果相同,那就意味着我们要写的寄存器已经被用了,但是这时前面获得的值显然是错误的,这时候直接转发过去就好了
这里还要考虑优先级的问题,越靠近这条指令,得到的数据就越新,我们就越倾向于优先使用这些数据
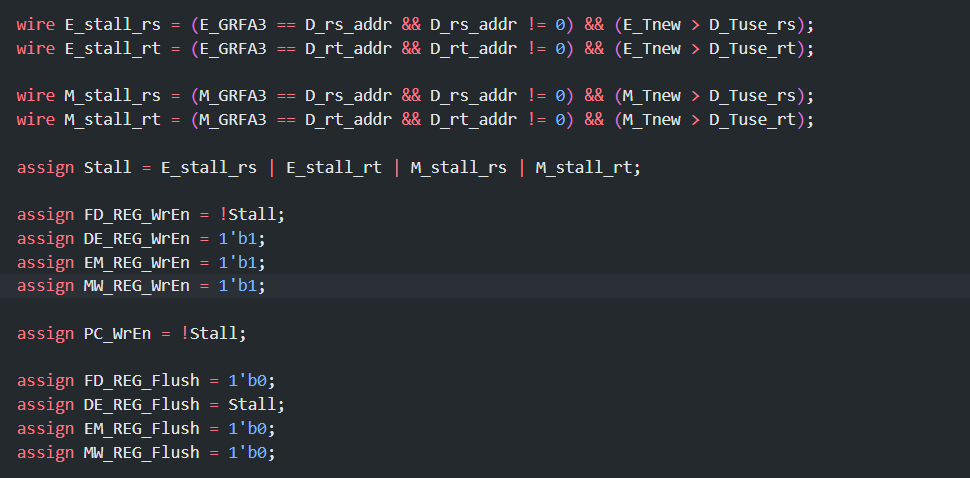
利用 AT 法,如果不阻塞就意味着一定能够在使用该寄存器的值之前获得正确的值,这就是 T 的作用,对于每一条指令,我们都维护他需要用 rt 和 rs 两个寄存器的时间 和,即再经过 个周期之后,我们需要用 rs 寄存器里的值;同时我们也去维护指令(如果要写入寄存器的话),啥时候值才会被算出来,即 个周期后我们才能算出正确的 GRFWD ,才能做转发
如果我们要用的时候,这个正确的值还没有算出来,那肯定不行,这时候我们就阻塞,如果能算出来,那么之前转发的错误的值不用去管它,最后总能得到一个正确的值去覆盖原先错误的值
如果我们还不知道要写的值是啥,那这个时候 GRFA3 就给正确的地址, GRFWD 就给 32'bz ,这时还不能做转发,但是如果写的阻塞模块正确,这个值就不可能被转发,因为这种情况如果出现就已经被阻塞在 D 级了
如果我们连要写哪个地址都不知道(课上加的指令可能会是这种情况),那就直接在 D 级暴力阻塞,肯定也不会被执行,从而得到转发的数据
转发逻辑的关键代码如下:
W-D 级转发在寄存器内部实现,寄存器内部转发一定要做

# 阻塞
对于阻塞的处理,直接采用教程中 和 进行判断的方法,设计一个 stall_CTRL 模块,专门负责处理阻塞时流水线寄存器的 flush 和 WrEn 信号就行
只可能在 D 级进行阻塞,阻塞控制器接受 D,E,M 级的指令输入,处理分析指令类别,并给他们赋上不同的 和 的值,然后用组合逻辑判断,如果 就直接阻塞 D 级,直到 时再继续执行
其实上面说这么多也未必讲的明白,直接去 Github 参考一些学长的代码,然后自己造几组数据看看波形,到底指令是怎么流水的,转发了什么,啥时候阻塞,然后自己再搭,就大部分都清楚了
# 思考题参考答案
# 流水线冒险
- 在采用本节所述的控制冒险处理方式下,PC 的值应当如何被更新?请从数据通路和控制信号两方面进行说明。
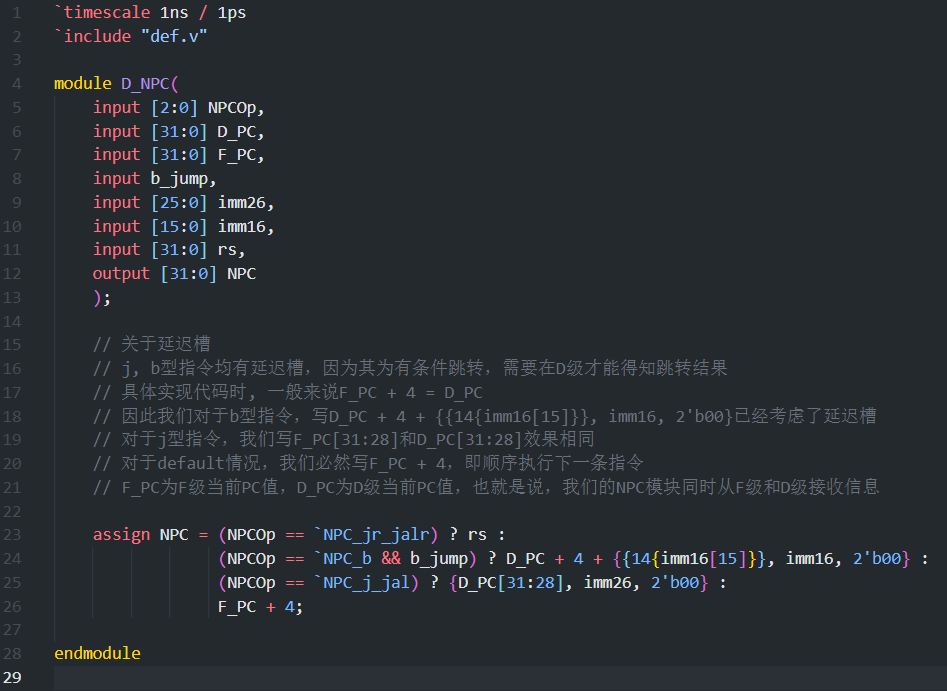
如图所示,直接利用 NPCOp 控制信号维护下一周期的 PC 值,其中有四种可能性即 branch 型, jr/jalr 型, j/jal 型和 PC+4 型
- 对于 jal 等需要将指令地址写入寄存器的指令,为什么需要回写 PC+8 ?
需要考虑延迟槽,在跳转指令后面后面有 nop 或者一条数据无关的指令。
# 数据冒险的分析
为什么所有的供给者都是存储了上一级传来的各种数据的流水级寄存器,而不是由 ALU 或者 DM 等部件来提供数据?
如果从非流水线寄存器部件转发,那么某一级的总延迟就会增加,从而根据木桶效应,时钟周期就会增加,总效率反而降低,得不偿失。
# AT 法处理流水线数据冒险
“转发(旁路)机制的构造” 中的 Thinking 1-4;
如果不采用已经转发过的数据,而采用上一级中的原始数据,会出现怎样的问题?试列举指令序列说明这个问题。
计算过程或存储过程中会用到还未更改过的寄存器值,从而出错。例如:
ori $1, $0, 1 nop nop nop nop lw $1, 0($0) nop sw $1, 4($0)这时,当指令
sw达到 M 级时,lw已经执行完毕,不会转发,但是我们有没有保留 E 级已经转发过的数据,这样sw指令就会把 1 存到 DM 中。我们为什么要对 GPR 采用内部转发机制?如果不采用内部转发机制,我们要怎样才能解决这种情况下的转发需求呢?
GPR 采用内部转发机制相当于 MW 流水线寄存器的值直接实时反馈到 GPR 的输出端,从而当前处于 D 级的指令可以直接用到对应寄存器的值,即 W 级到 D 级的转发。
如果不采用内部转发机制,需要额外建立从 MW 流水线寄存器转发到 D 级的数据通路。
为什么 0 号寄存器需要特殊处理?
因为指令可以对 0 号寄存器赋值,只是不会造成实际作用,但是转发过程中如果不特判就默认 0 号寄存器的值被更改了,从而造成错误。
什么是 “最新产生的数据”?
根据指令的执行顺序,越后执行的指令更改的寄存器的值越新,按照 DE、EM、MW 的顺序,越靠前所转发出的信息越新,因此优先级更高。
在 AT 方法讨论转发条件的时候,只提到了 “供给者需求者的 A 相同,且不为 0”,但在 CPU 写入 GRF 的时候,是有一个 WE 信号来控制是否要写入的。为何在 AT 方法中不需要特判 we 呢?为了用且仅用 A 和 T 完成转发,在翻译出 A 的时候,要结合 WE 做什么操作呢?
AT 法要求:只要当前位点的读取寄存器地址和某转发输入来源的写入寄存器地址相等且不为 0
那么既然是要写入的,WE 必然为 1,因此不用特判,如果不需要写入,我们零待写入地址
GRFA3为 0,向 0 号寄存器里写入数据相当于不写如果 WE 是 0,我们把
GRFA3设为5'b00000即可
# 在线测试相关说明
在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
此思考题请同学们结合自己测试 CPU 使用的具体手段,按照自己的实际情况进行回答。
我的测试方法是利用随机生成数据进行大范围测试,对于随机数据无法覆盖的点,通过手动构造特殊样例进行测试
对于随机数据生成,我采用了对于指令进行分类,进行测试,生成的指令仅包括
$1,$2,$3,$31,$4,$5这些寄存器,以增加相邻指令寄存器复用的概率,提高冲突发生的概率生成器采用教程中所述的公共跳转区的做法,即
# 刚开始用ori和lui对寄存器赋初始值 jal subtest1 back1: jal subtest2 back2: endtest: beq $0, $0, endtest subtest1: # 这里生成长度约为10~15条的随机指令 # 为了避免死循环,beq指令均跳转到endsubtest处 endsubtest1: la $ra, back1 jr $ra subtest2: # ... endsubtest2: la $ra, back2 jr $ra根据最终覆盖性测试的结果,生成的指令有以下部分未被覆盖,大部分是 load 指令,这是因为 load 指令的地址处理难以解决的原因
![image-20211123170331326]()

对于这些指令,我们采用手动构造测试样例进行测试即可
- 总结来看,随机数据生成加上一定的策略可以进行处理大量的冒险类型,但是对于无法覆盖的,就需要手动构造样例
- 手动构造样例时可以考虑转发的来源和接受源,以全面测试
- D 级需求: E->D (如序列
jal-addu), M->D (如序列jal-nop-addu)(W->D 隐藏于 GRF 的内部转发中) - E 级需求: M->E (如序列
addu-addu), W->E (如序列addu-nop-addu) - M 级需求: W->M (如序列
addu-sw)
- D 级需求: E->D (如序列